User-friendly scaling
Back in the mists of time, whilst programming early versions of Canoco, Cajo ter Braak decided to allow users to specify how species and site ordination scores were scaled relative to one another via a simple numeric coding system. This was fine for the DOS-based software that Canoco was at the time; you entered 2 when prompted and you got species scaling, -1 got you site or sample scaling and Hill’s scaling or correlation-based scores depending on whether your ordination was a linear or unimodal method. This system persisted; even in the Windows era of Canoco these numeric codes can be found lurking in the .con files that describe the analysis performed. This use of numeric codes for scaling types was so pervasive that it was logical for Jari Oksanen to include the same system when the first cca() and rda() functions were written and in doing so Jari perpetuated one of the most frustrating things I’ve ever had to deal with as a user and teacher of ordination methods. But, as of last week, my frustration is no more…
…because we released a patch update to the CRAN version of vegan. Normally we don’t introduce new functionality in patch releases but the change I made to the way users can request ordination scores was pretty trivial and maintained backwards compatibility.
Previously, different scalings could be requested using the scaling argument. scaling is an argument of the scores() function; anything function using scores() would either have scaling as a formal argument too, or would pass scaling on to scores() internally. To date, the different scores were specified as per DOS-era Canoco as numeric values. Now, scores() accepts either those same old numeric values or a character string for scaling coupled with a second logical argument. Vegan accepts the following character values to select the type of scaling:
"sites", which gives site-focussed scaling, equivalent to numeric value1"species"(the default), which gives species- (variable-) focused scaling, equivalent to numeric value2"symmetric", which gives a so-called symmetric scaling, and is equivalent to numeric value3.
To get negative versions of these values, the correlation or hill argument should be set to TRUE as follows
correlation(defaultFALSE) for correlation-like scores for PCA/RDA/CAPSCALE models, orhill(defaultFALSE) for Hill’s scaling for CA/CCA models
Whilst this requires the setting of two different arguments, it’s certainly a lot easier to remember these two arguments than what the numerical codes mean.
Obligatory Dutch dune meadows example
Here’s a quick example of the new usage showing a PCA of the classic Dutch dune meadow data set.
library("vegan")Loading required package: permute
Loading required package: lattice
This is vegan 2.3-1data(dune)
ord <- rda(dune) # fit the PCA
layout(matrix(1:2, ncol = 2))
plot(ord, scaling = "species")
plot(ord, scaling = "species", correlation = TRUE)
layout(1)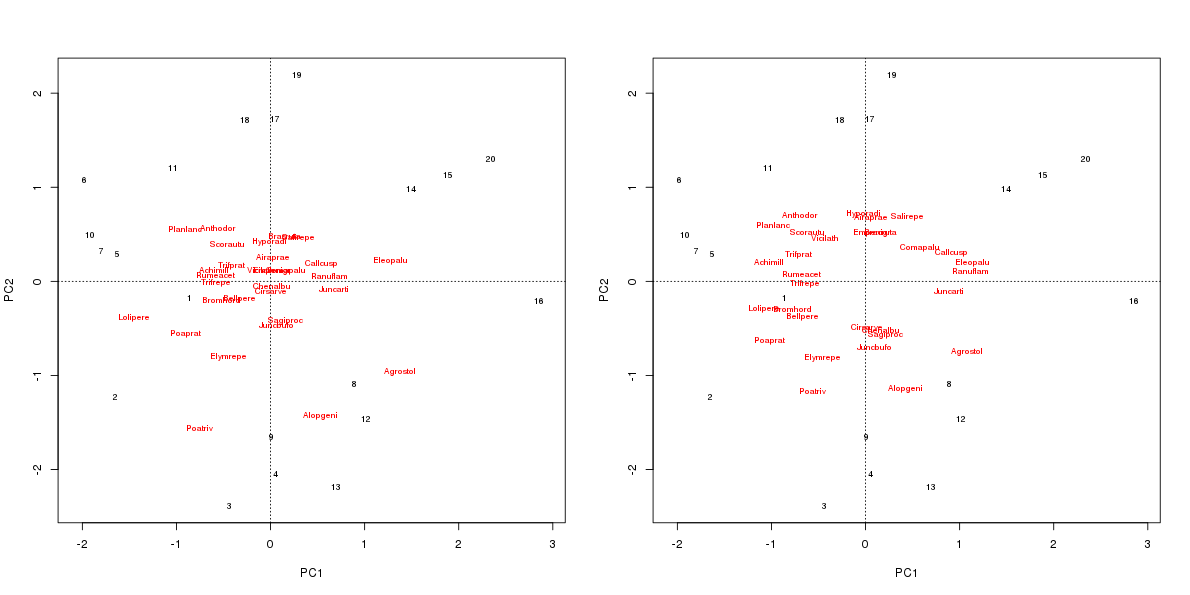
The two biplots are based on the same underlying ordination and both focus the scaling on best representing the relationships between species (scaling = "species"), but the biplot on the right uses correlation-like scores. This has the effect of making the species have equal representation on the plot without doing the PCA with standardized species data (all species having unit variance).





